왜 파워비아이 에서 데이터 전처리가 필요한가?
데이터 전처리가 필요한 이유는 아주 간단하고 명확합니다. 엑셀이나 웹상에서 가지고 온 데이터는 바로 파워비아이에 사용할 수가 없기 때문이죠.
회사에서 가장 많이 사용되는 것이 엑셀이기 때문에 엑셀을 예로 들겠습니다. 스프레드시트의 대명사로 통하며, 회사에서 서류를 만들 때 없어서는 안 될 소프트웨어가 엑셀이라는 건 다들 공감하실 겁니다. 또한 여러 데이터분석 프로그램에서 엑셀 시트를 불러와 데이터 작업을 할 만큼 널리 사용되는 소프트웨어이기도 하지요.
특히 숫자를 다룰 때는 타의 추종을 불허한다고 해도 과언이 아니며 셀 안에 있는 숫자나 문자를 사용자가 원하는 대로 꾸밀 수 있다는 것은 엑셀의 가장 큰 장점입니다. 하지만 이러한 장점이 데이터 분석에 있어서 단점으로 바뀌게 되는데요, 너무나 자유로운 편집이 데이터 분석에 있어서 걸림돌이 된다는 것입니다. 그래서 이러한 ‘자유’를 파워쿼리 에디터에서 ‘구속’으로 바꾸어 줘야 데이터 분석에 이용할 수 있습니다.
데이터를 다루는데 엑셀과 파워쿼리 에디터의 차이점은 다음과 같습니다.
- 엑셀: 사용자가 원하는 대로 데이터를 구성
- 파워쿼리 에디터: 파워비아이가 원하는 데로 데이터를 구성
즉 엑셀은 사용자가 주체이지만, 파워쿼리 에디터는 데이터 형식을 파워비아이가 원하는 데로 맞추어 줘야 한다는 것입니다.
간단한 예를 들겠습니다.
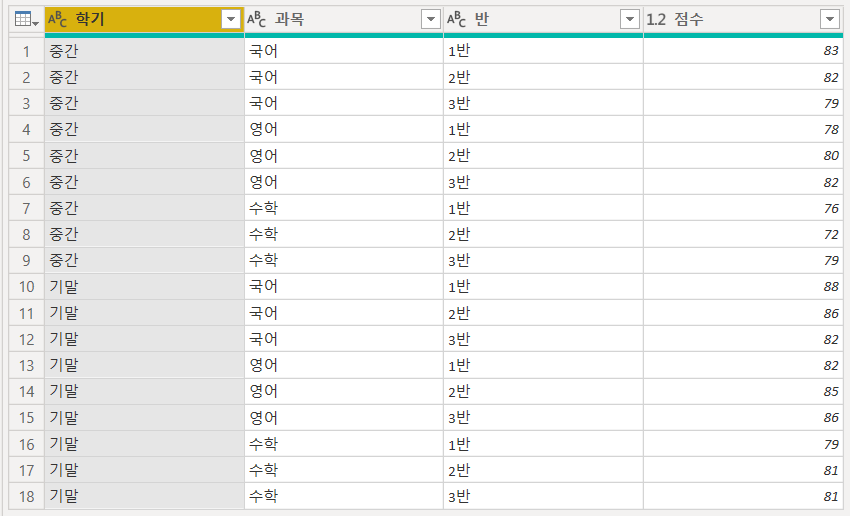
반별 국, 영, 수 점수의 중간, 기말별 평균성적을 나타낸 표입니다. 우리가 늘 접하는 형식이죠. 하지만 불행하게도 이러한 표는 데이터 분석을 위해서 사용이 될 수 없습니다.

데이터 분석을 위해서는 전처리를 통해 아래와 같이 변형이 되어야 파워비아이에서 시각화 작업이 가능합니다.
데이터 전처리의 가장 기본은 행에 포함되는 열의 구성이 유니크 (Unique)한 구성을 가져야 한다는 것입니다.
여기서 예를 들면 첫 번째 행은 {중간, 국어, 1반, 83} 이고 두 번째는 {중간, 국어, 2반, 82}, 이런 식으로 총 18개의 행을 가진 데이터입니다.
다시 말해서 {학기, 과목, 반, 점수}로 구성된 18개의 행의 데이터가 중복 없이 구성되어야 합니다.
아까 말씀드린 엑셀에서 작성한 표를 파워쿼리 에디터로 가지고 와 {학기, 과목, 반, 점수}로 구성된 하나의 데이터로 ‘구속’을 시켜주는 작업이 데이터 전처리 과정입니다.
데이터를 ‘구속’시키는 이유는 아주 간단합니다.
지금 예제로 다루는 데이터는 몇 줄 안 되는 데이터지만, 수만 아니 수십만 개의 데이터를 다루려면 아주 강한 규칙이 필요하며, 데이터 분석의 오류를 없애기 위한 일련의 조치입니다.
이는 파워쿼리를 이용해 전처리를 진행하면 자연스럽게 알 수 있는 것이므로 지금은 이 정도로만 설명하겠습니다.
하지만 데이터 전처리가 되었다고 시각화를 위한 준비가 끝난 것은 아니고 전처리된 데이터를 다시 여러 수식을 이용해 필요한 값을 추출하는 과정이 필요합니다. (편의상 후처리라 하겠습니다)
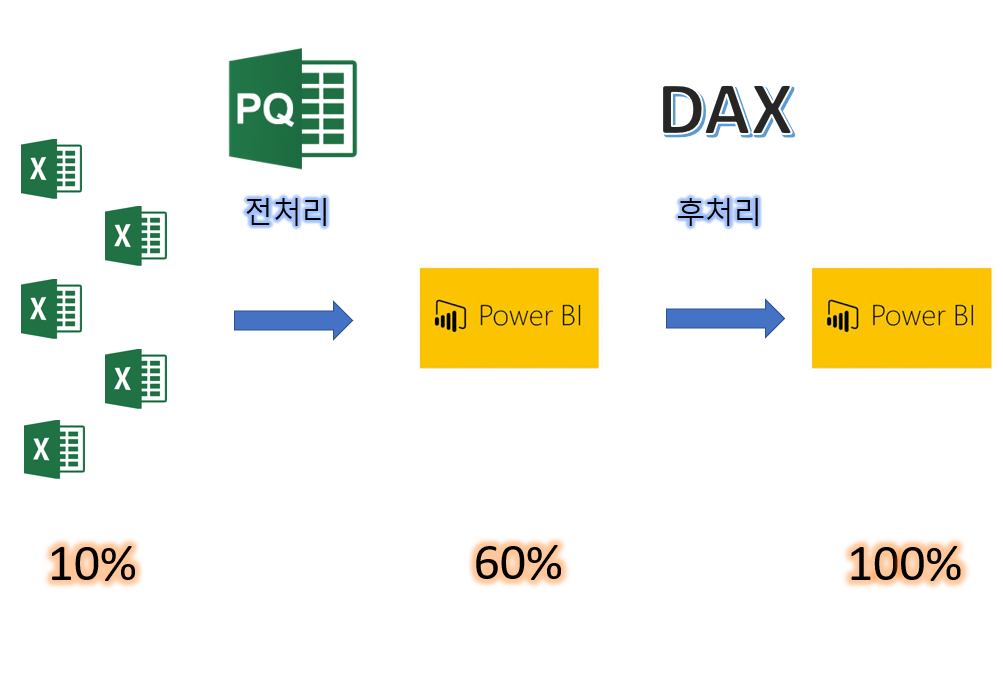
아래의 그림을 마지막으로 이 글을 마무리하겠습니다.
엑셀 데이터도 가공하지 않고 사용할 수 있지만, 이는 극히 드물다고 생각해야 하며, 파워쿼리 에디터를 이용해 데이터 전처리를 하면 원하는 표와 그래프 및 값을 얻을 수 있지만 사실 이것으로도 부족하며, DAX라는 수식을 이용해 데이터 후처리까지 진행해야 거의 원하는 모든 값을 얻을 수 있습니다.
편의상 10%, 60%, 100%라고 했지만, 파워쿼리 에디터에서도 잘 가공을 한다면 거의 90% 가까이 원하는 결과를 얻을 수 있습니다. 하지만 이것도 어느 정도 한계는 있으며, DAX를 이용한 후처리가 필요한 경우가 대부분을 차지하기 때문입니다.