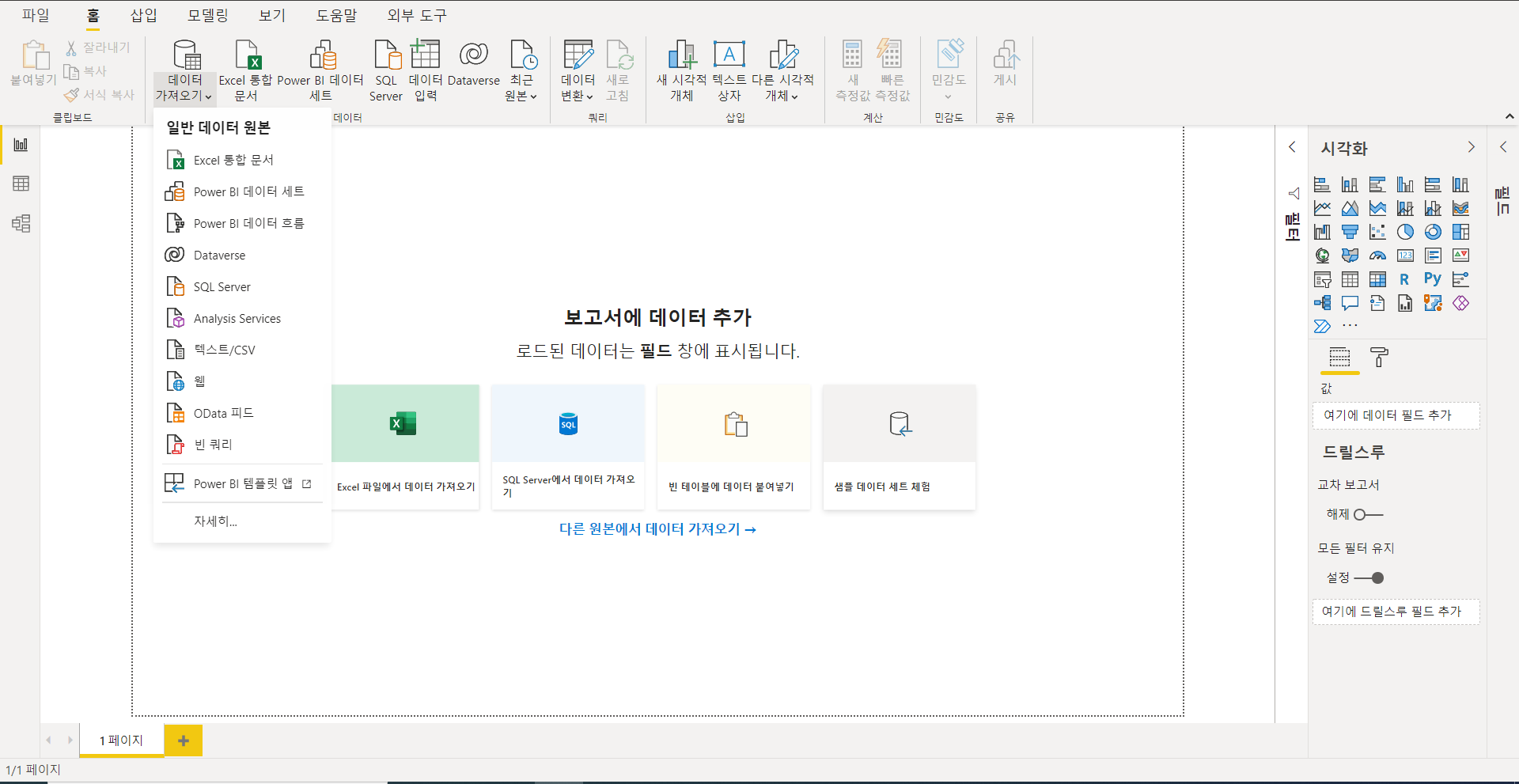
먼저 데이터 전처리를 시작하기 전 파워쿼리 에디터의 구성에 대해서 잠시 살펴보겠습니다. 엑셀과 비슷하게 생겼지만, 완전히 다른 구조를 가졌으므로 머릿속에서 엑셀에 대한 생각을 지워야 보다 쉽게 다가갈 수 있습니다.
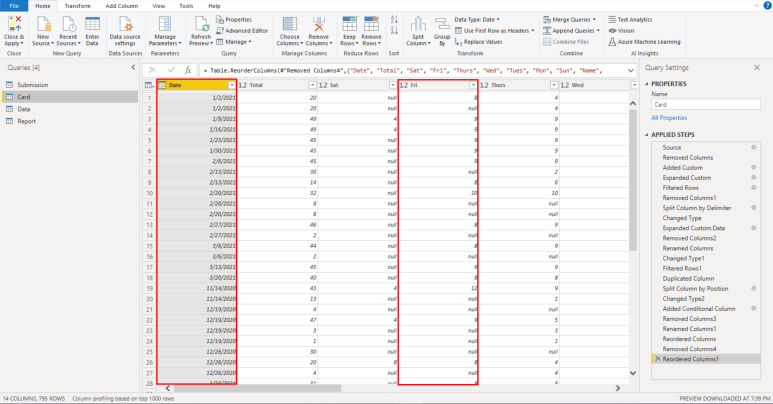
파워쿼리 에디터는 아래와 같이 5개의 영역으로 나눌 수 있습니다.
- 쿼리 에디터 리본 (Query Editor Ribbon) - 데이터 수정 작업을 실행하는 명령 버튼 (복잡한 프로그래밍 언어를 간단히 버튼 클릭으로 수행할 수 있도록 도와줍니다)
- 쿼리 창 - 현재 쿼리 에디터에 있는 쿼리 리스트
- 작업 창 - 진행된 작업의 결과물을 보여주는 창
- 쿼리 설정 - 현재 작업 중인 쿼리 이름과 적용된 단계를 보여주는 창
- 상태 바 - 셀에 있는 내용을 보여주는 창
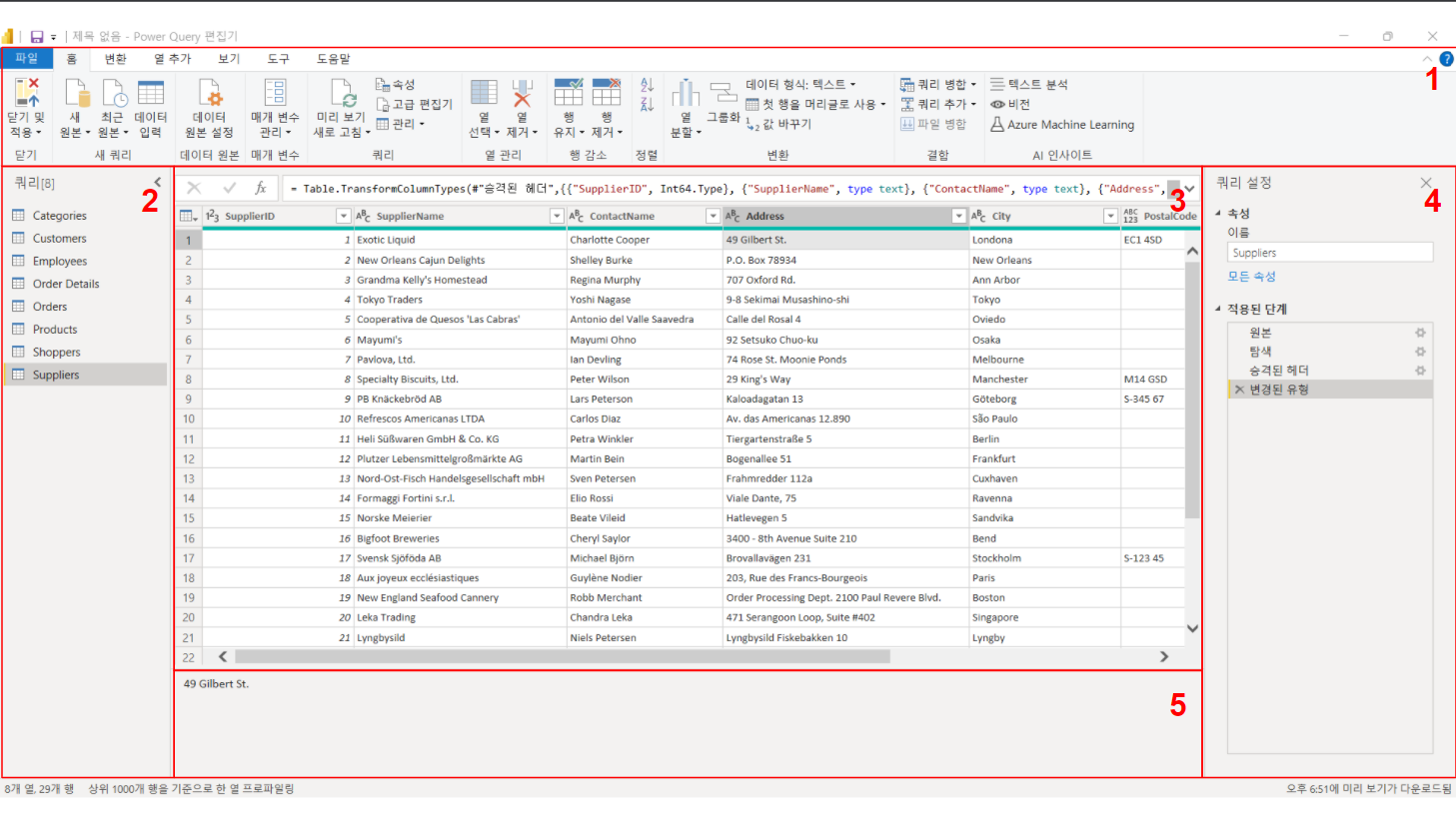
작업 창과 적용된 단계에 대해 잠시 말씀드리겠습니다.
작업 창
작업 창은 지금까지 진행된 결과물을 시각화시킨 창으로 사용자가 보다 편하게 결과물을 확인해가며 데이터 변환을 할 수 있도록 도와주는 창으로, 결과물이 친숙한 엑셀 형태로 보여주니 좀 더 직관적으로 작업을 진행할 수 있습니다.
파이썬 (Python)의 경우도 데이터 변환을 수행할 때 Jupyter Notebook을 많이 사용하는데, 이것도 마찬가지로 코딩한 결과물을 파워쿼리 에디터의 작업 창처럼 테이블이나 차트로 바로 보여주는 기능을 가지고 있기 때문에 데이터 전처리 과정에서 많이 사용되는데, 실행한 명령의 결과를 바로 확인하며 작업할 수 있는 환경을 제공한다는 것은 사용자 입장에서는 만점에 가까운 기능이라 할 수 있습니다.
적용된 단계 창
적용된 단계를 보여주는 창은 가장 중요한 부분이라 생각하는데, 지금껏 데이터 변환을 위해 입력한 명령을 단계별로 저장해 어떤 단계를 거쳐 지금의 결과물을 가지고 왔는지 일목요연하게 리스트로 보여줍니다. 적용된 단계는 M-Code (M 언어라고도 합니다)로 구성된 명령어를 수식 창에 보여주며, 이에 대한 결과물은 바로 작업 창에 보여주는 형태입니다. 아주 편한 점은 지금껏 작업한 단계가 그대로 기록이 되기 때문에 원하는 단계로 이동이 가능하다는 것입니다.
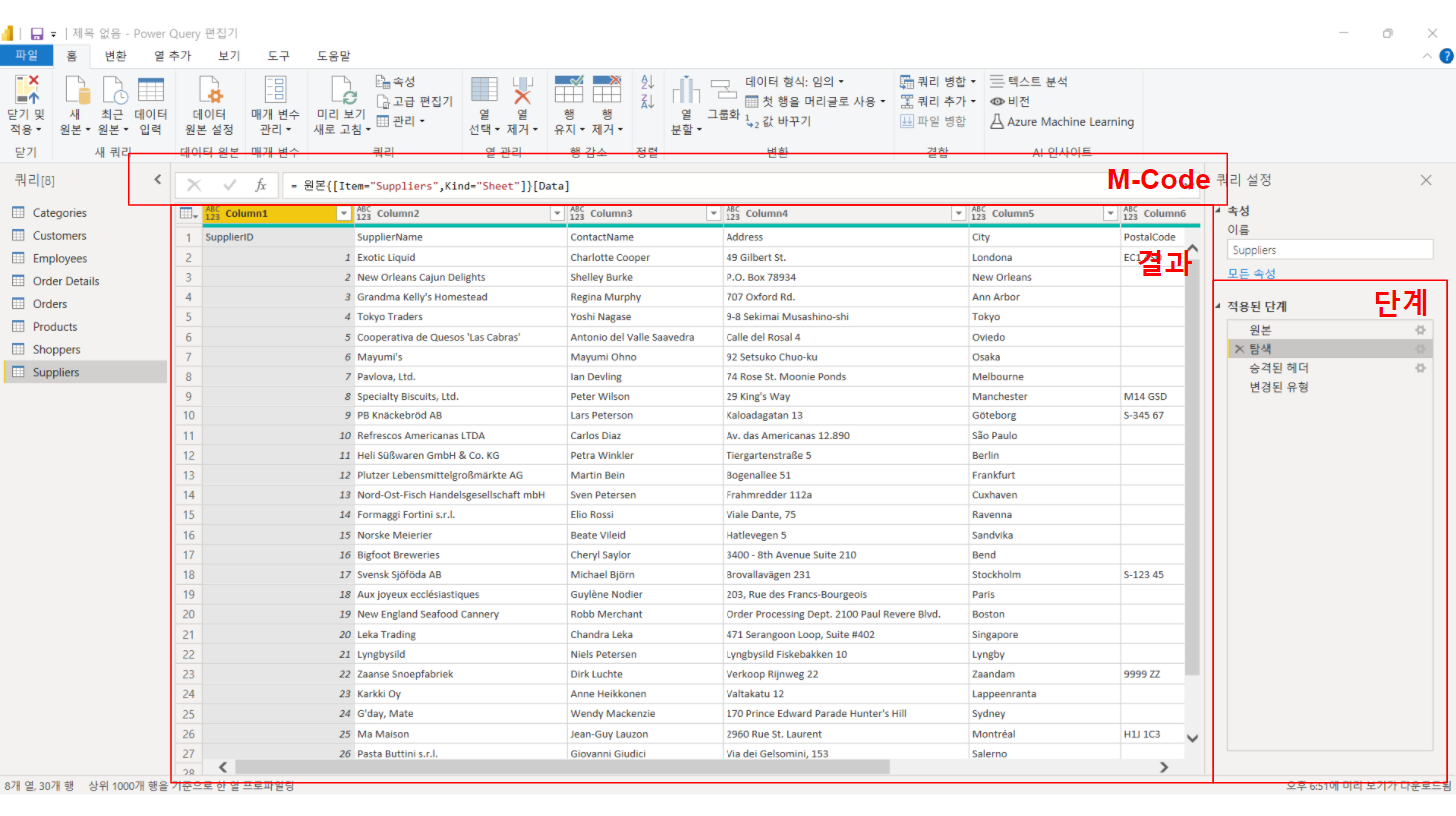
위의 이미지와 같이 “탐색’을 선택하면 “탐색” 명령에 사용된 M-Code가 수식 창에 나타나며, “탐색” 명령이 실행된 뒤의 결과물을 동시에 작업 창에 보여줍니다. 이곳에 다른 명령을 추가하고 싶으면 추가도 가능하고, 필요 없는 부분은 삭제도 가능하며, 수정도 가능합니다.
쿼리의 적용된 단계를 설명하자면 글이 너무 길어질 것 같으니 다음번에 자세히 다루도록 하겠습니다.
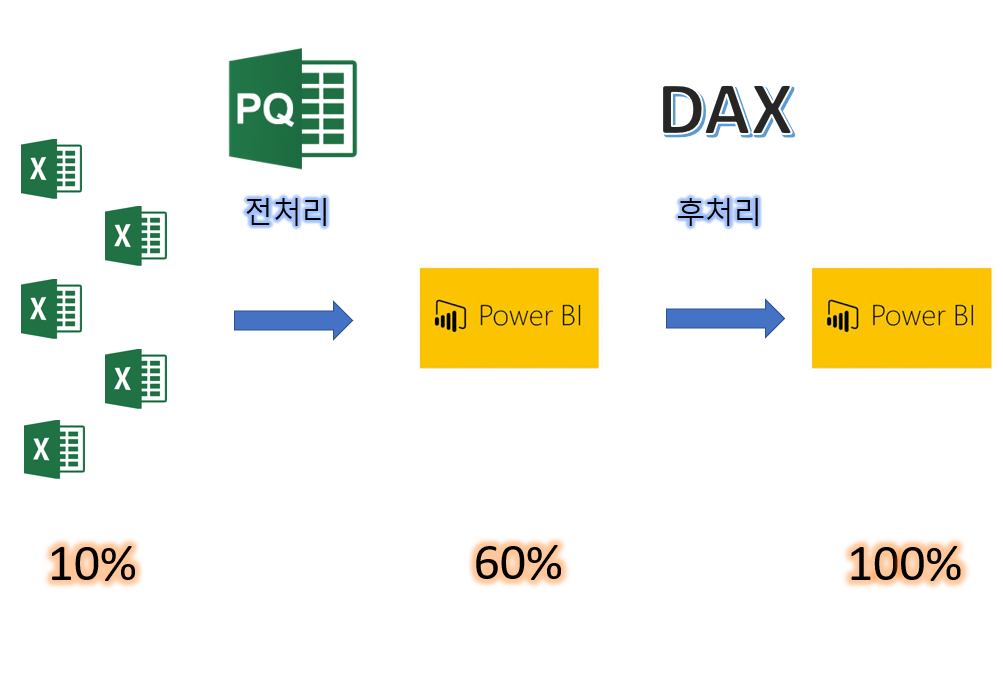
이렇게 구성된 쿼리 에디터를 이용해 데이터 전처리를 진행하여 일반 데이터를 파워비아이가 원하는 데이터로 형태를 바꾸면 파워비아이의 보고서 창에서 데이터 시각화에 사용이 가능하게 됩니다.
'파워쿼리 > 데이터 전처리와 파워쿼리' 카테고리의 다른 글
| 파워쿼리 데이터 전처리에서 꼭 해야 할 것 - 오류 및 결측치 확인 및 제거 (0) | 2021.12.24 |
|---|---|
| 파워쿼리 에디터 - 적용된 단계 창에서 알아 두어야 할것 (0) | 2021.12.20 |
| 데이터 전처리의 첫번째 단계 - 파워쿼리 에디터에 데이터 가지고 오기 (0) | 2021.12.13 |
| 왜 파워비아이 에서 데이터 전처리가 필요한가? (0) | 2021.12.12 |
| 야근이 필요 없습니다 - 데이터 전처리 이제 시작하자 (0) | 2021.11.20 |