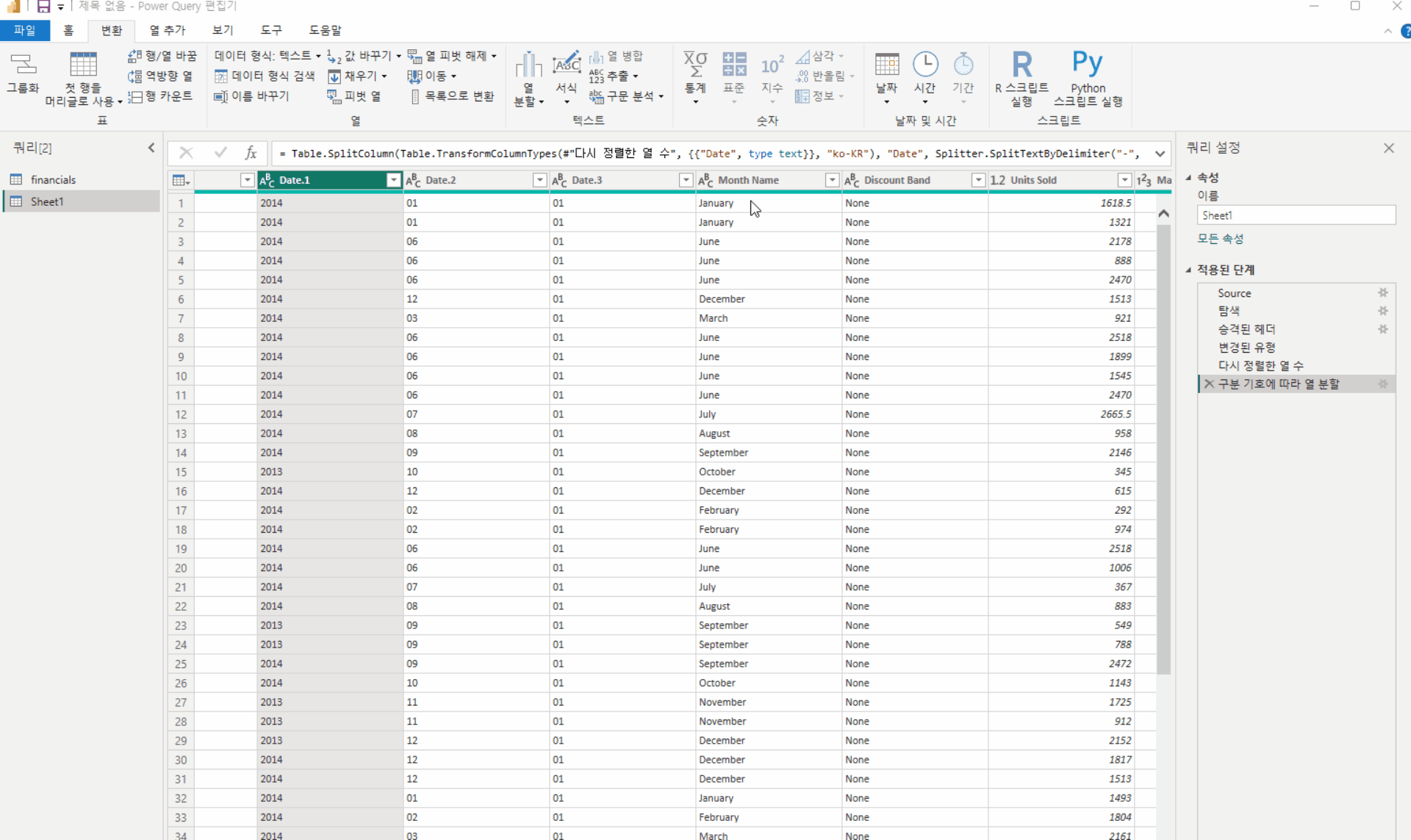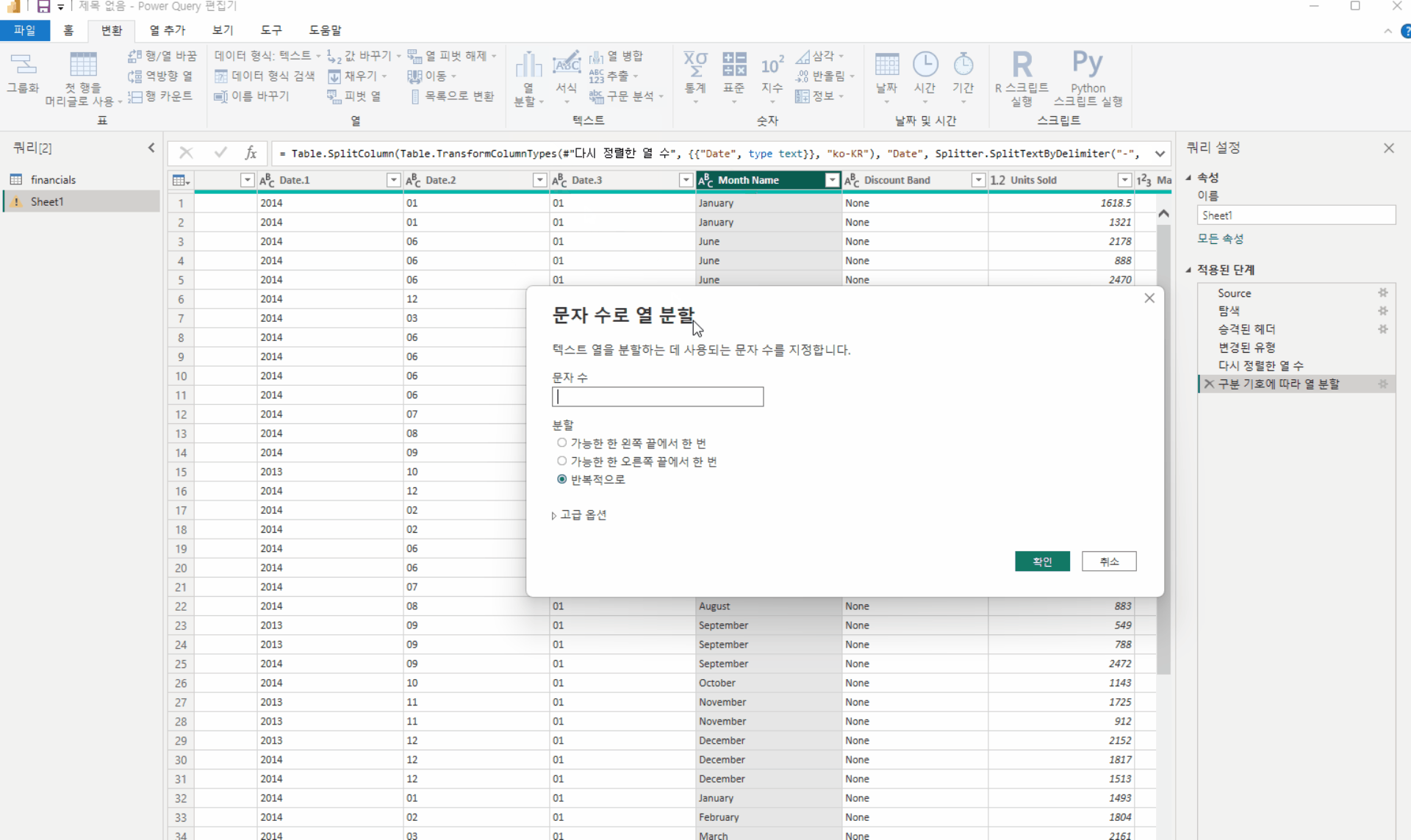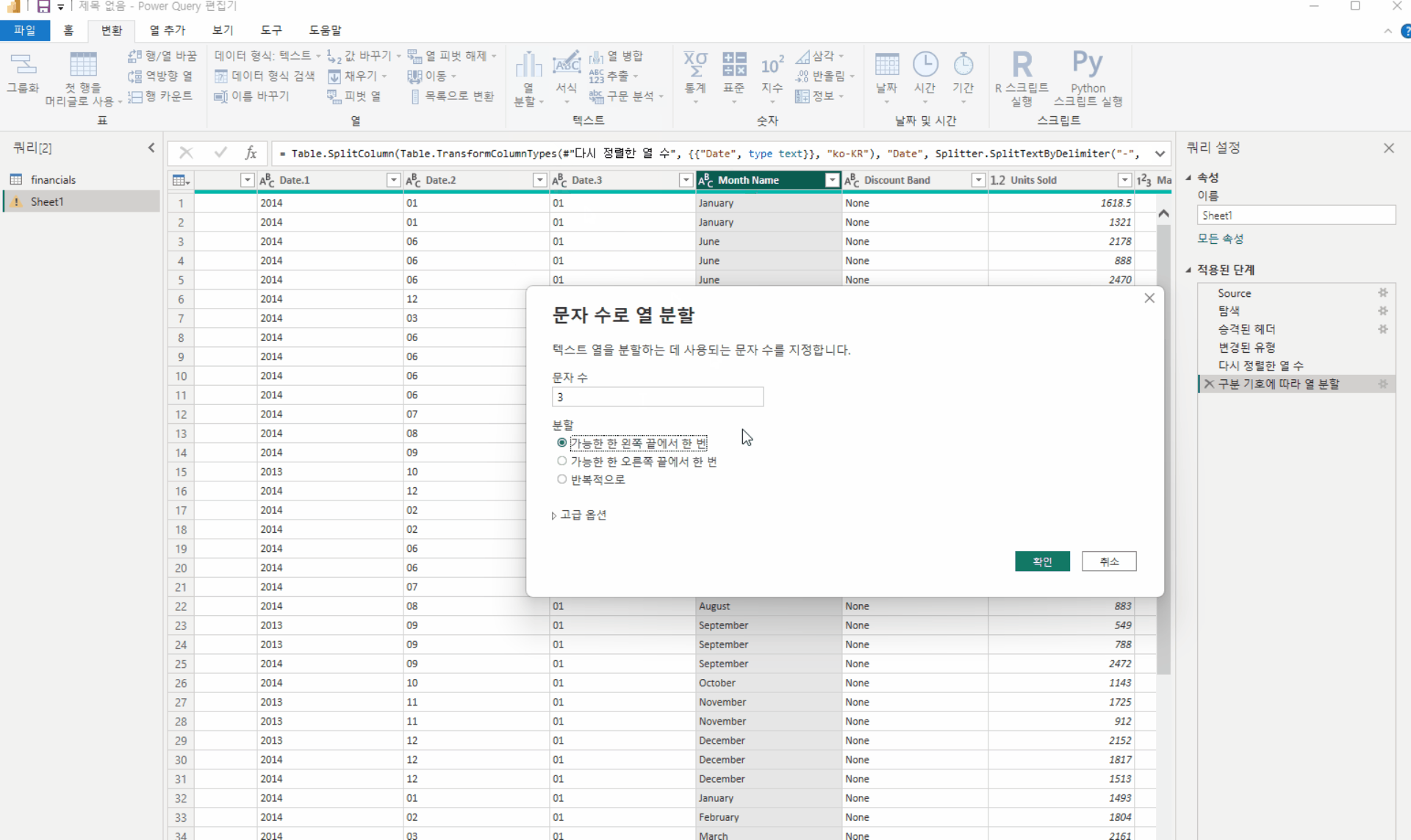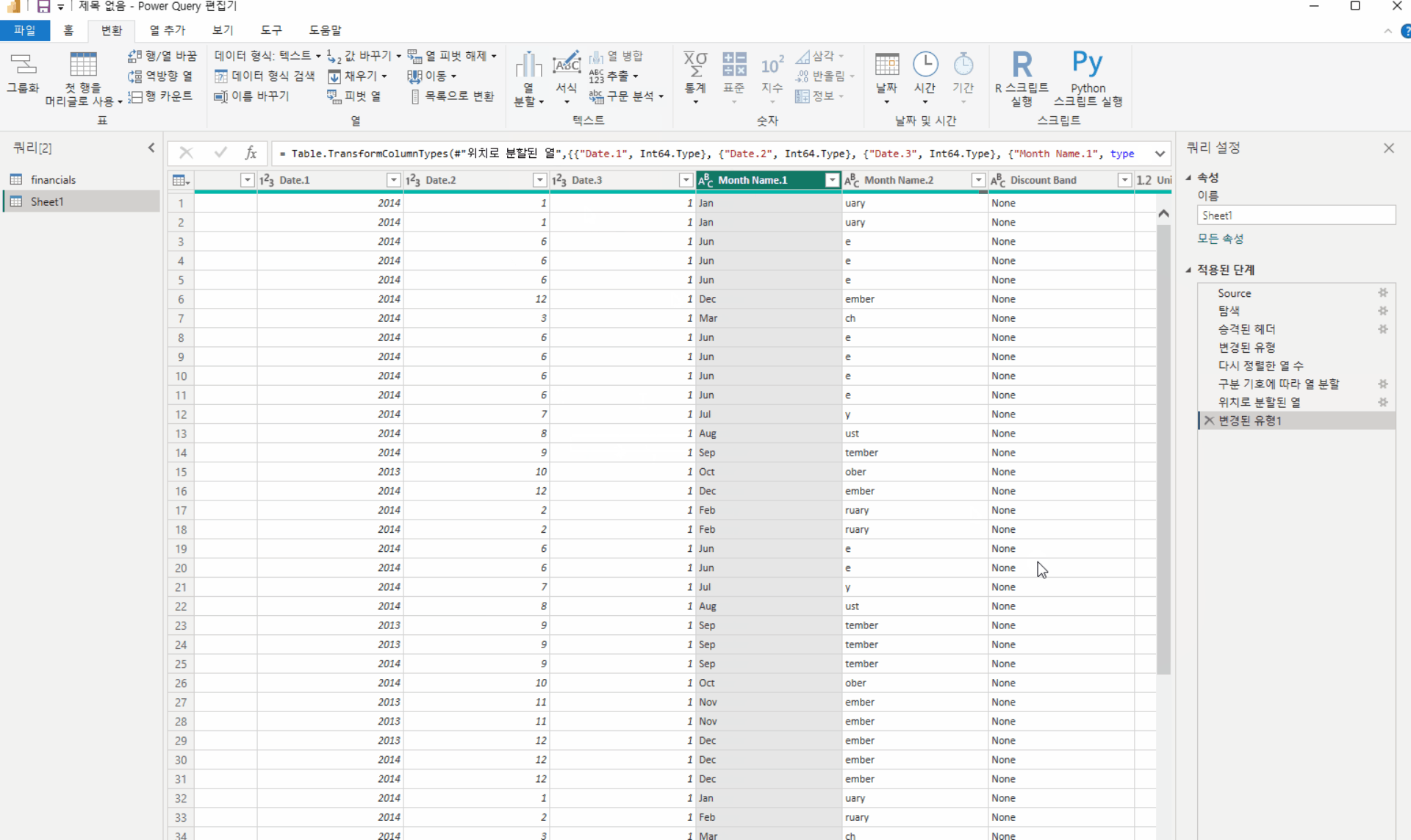
파워비아이 보고서 페이지에서 작업 시, 데이터 필터링을 위해 슬라이더를 활용하는 경우가 많습니다. 슬라이서에 데이터가 많지 않으면 모든 리스트가 슬라이서에 표시가 되지만, 과도한 데이터가 포함되어 있다면 슬라이서내에 모든 데이터가 표시되기는 어렵습니다.
이 경우 아래와 같이 오른편에 있는 스크롤바를 활용해 데이터를 찾아야 하는 번거로움이 발생할 수 있습니다.
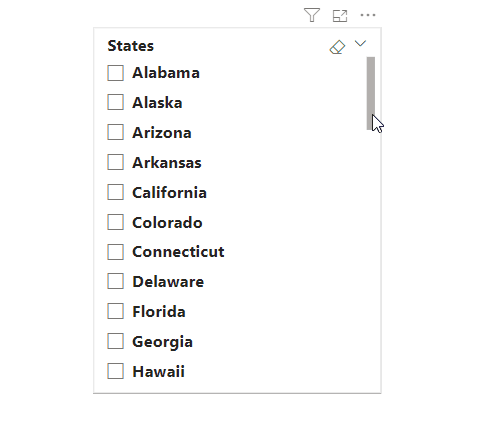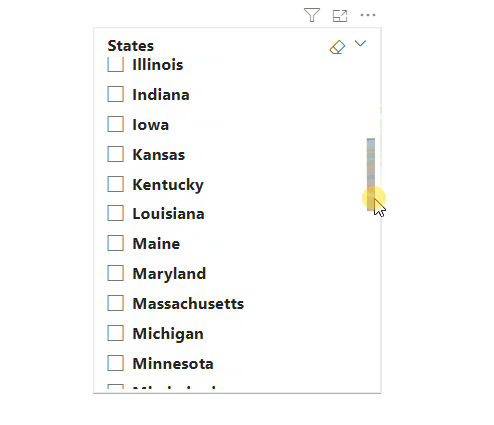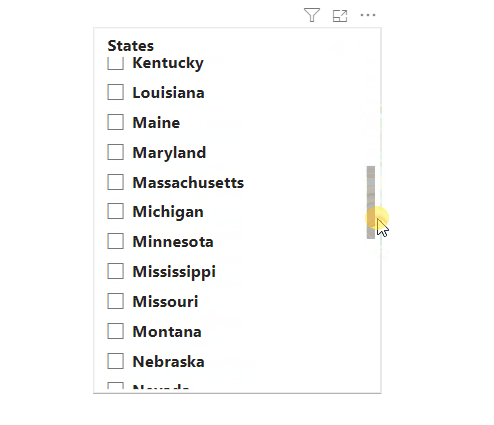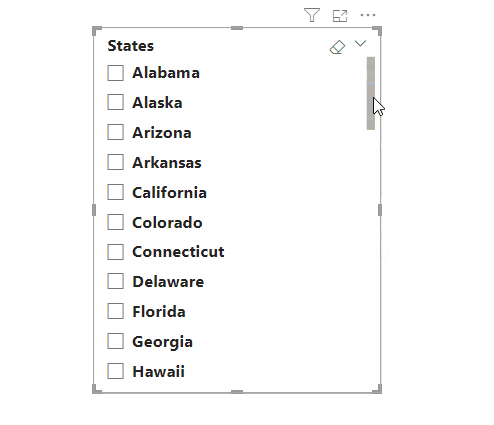
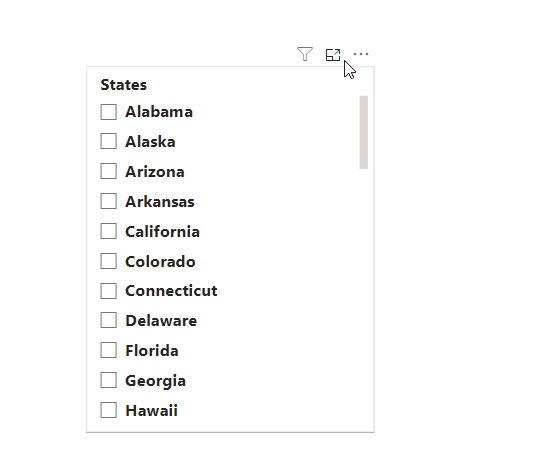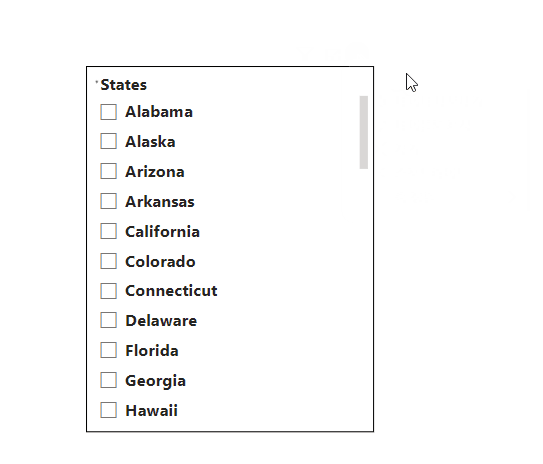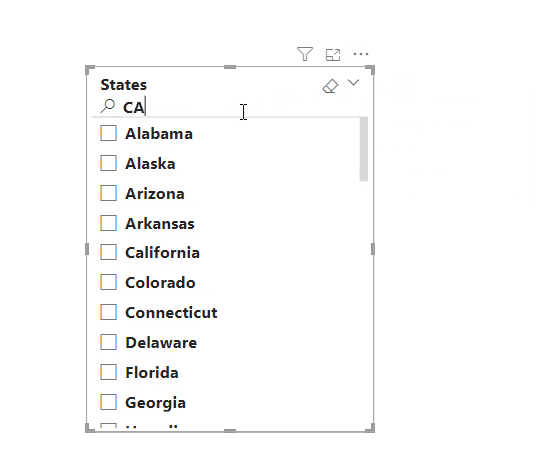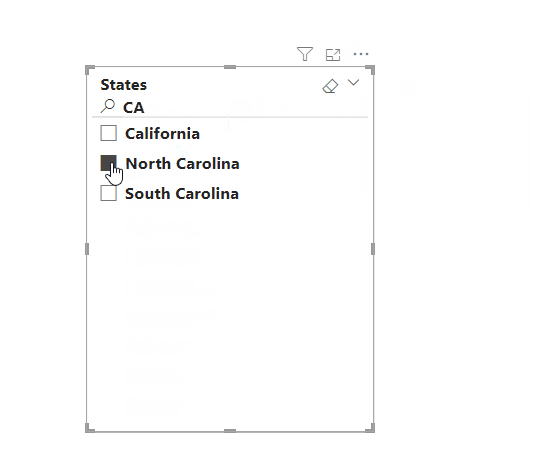
미국의 주를 데이터로 활용하여 슬라이더를 생성하려고 할 때, 총 50개 이상의 데이터가 있기에 이 또한 슬라이더 내에서 모든 데이터를 동시에 표시할 수 없습니다. 이러한 상황에서 슬라이더에 '검색' 기능을 활성화하면 데이터를 보다 간편하게 검색할 수 있습니다.
검색창 활성화
슬라이더 내 검색 창은 기본적으로 감춰져 있으며 활성화하면 즉시 활용할 수 있습니다. 예를 들어, North Carolina 주를 슬라이더 내에서 검색 후 선택하고자 할 경우, 다음 단계를 따라 검색 창을 활성화하고 검색창을 통해 North Carolina 주를 빠르게 찾을 수 있습니다:
- 오른쪽 상단에 있는 세 개의 점을 클릭하여 추가 옵션 메뉴로 이동합니다.
- 이곳에서 최상단에 있는 '검색' 옵션을 선택하면 검색 창이 즉시 표시됩니다.
- 검색 창에 원하는 데이터를 입력하고 해당 데이터를 선택합니다.
시각적 개체 슬라이더의 숨겨진 기능에 대해 살펴보았습니다. 이러한 유용한 기능들이 여러 곳에 숨어 있으며, 숨겨진 기능을 제대로 활용한다면 작업을 더욱 효율적으로 수행하는 데 도움이 될 것입니다.
'파워비아이 > 파워비바이 이야기' 카테고리의 다른 글
| 파워비아이가 엑셀보다 좋은점 (0) | 2021.03.27 |
|---|